by Daniel Erasmus
In 2010 an integrated oil and gas company defined a set of themes called the Future Energy Technologies to track the emergence of new energy technologies. These future energy technologies represent investment opportunities or areas to track in the outside world. In 2011 this company’s breakthrough innovation group used the unique big data analytical tool Erasmus.AI to map and track the Future Energy Technology themes. One of these themes was the emergence of Electric Mobility which maps the current and future demand for electric mobility. The map was generated and visualized as a 3 month snapshot in 2011 by the Erasmus.AI engine.
The Erasmus.AI engine ingests millions of articles every day from a seed list of over a billion URLs. This includes newspapers, social media, earnings calls, annual reports, scientific reports, grants, academic publications, clinical trials, patents, and so forth. The toolkit is built on the premise that the interrelationship between these normally disparate datasets will reveal new unique insights. The computing cluster is hosted in Amsterdam, and it is primarily a text analysis system. A team can interactively track viewpoints or themes in the dataset, receive reports, share insights, and collectively gain overview and insight into vast repositories of knowledge. The visualised texts are similar to maps. These visualisations are built up on the basis of extracted concepts (organisations, people, places, etc.) or linguistic similarity. In other words, similar articles tend to be closer together.
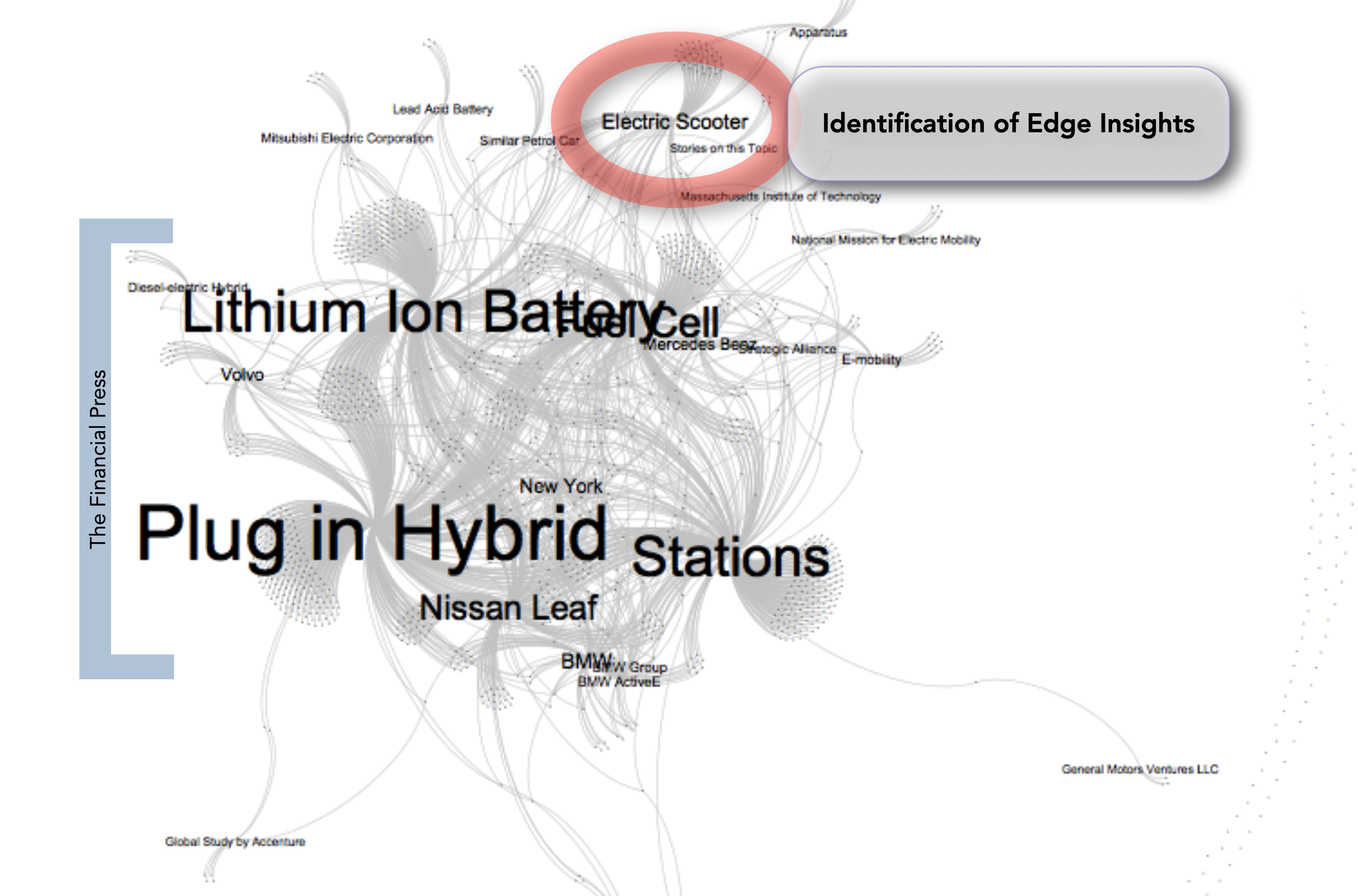
When thinking about electric mobility, in 2011, we think about plug-in hybrids, lithium-ion batteries, charging stations, range anxiety. Six years later, we would add Tesla, the amount of lithium in Bolivia and transition costs to the list. But, unless you spend an extraordinary amount of time looking for the edge, you will only see the centre. One has to recognise and find edge dwellers, grok their thoughts, learn their language, reflect on their underlying assumptions, and together with decision makers translate these insights into “modest positions”, as Paul Cilliers would call them. The good stuff as I call it, is right there, “over the hill and under the mountain”- but which hill, how deep to dig until we burst into the sunlight of a radical insight. Would Nokia have found Danny Hillis’ multi-touch zoomable table patent? With hard work perhaps, but not by looking towards the centre- flip phones.
New tools give us an opportunity to see the edge through radically different means. Less sweat, more silicon. Looking at electric mobility through the eyes of Erasmus.AI, a collective sensemaking tool, we see something analogous to a “mental map” of our collective thinking on electric mobility. The centre of the visualization is anchored by predictable signifiers: Plug-in Hybrid, Nissan Leaf, Lithium Ion Battery, Fuel Cell, etc. At the edge, a cluster set on Electric Scooters. Even today, half a decade later, the discussion about electric mobility still does not consider electric scooters as important. This is wrong.
Unless you spend an extraordinary amount of time looking for the edge, you will only see the center. I’m proposing a radically different approach: less sweat, more silicon.
This silicon nudge in the direction of electric scooters transitions to human analysis. The performance characteristics of the batteries with limited energy density and limited range are better suited for short light city trips- exactly the type of commute we see in Asian megacities. The youthful demographics of these cities implicate single person rather than multi-person journeys as prevalent in the “old West.” Sourcing: many of the batteries are being manufactured in close proximity to the cities. Congestion: as scooters command a fraction of the available roadway space, we can expect government policies to support them. Air quality: the brooding social conflict created by the air pollution burden in the Asian megacities imply governmental support for a shift to support electric scooters as an affordable, local approach to make this transition. Lastly disruptive innovation theory as exposed by Clayton Christensen imply that inferior niche products will move up the value chain, exploiting more and more valuable niches over time, to eventually dominate incumbents. Perhaps the electric cars of the future will not be Teslas or BMWs but some of those small scooter companies that dot China. We have just made the transition from looking at plug-in hybrids to seeing that there is a strong likelihood that electric mobility will first be dominated by scooters before cars.
At the scale of these datasets, if our systems do not learn, we will not learn.
This insight created through the combination of big data and human intelligence is the type of approach that I wrote about earlier when describing the 2005 Freestyle Chess games. It is Engelbart’s augmentation of human intelligence skilled at pattern recognition combined with the unprecedented overview from big data text analytics.
Just under a thousand times more electric scooters were sold than electric cars in China, three years after this analysis. In China 30-40 million electric scooters were sold in 2014. The aim is to have 350 million electric scooters on the road in China by 2018. To put this in perspective this is about than a third of the billion cars in the world. Calculations that blindly extrapolate car ownership, steel requirements, CO2 production from the newly affluent Chinese middle class are extrapolating the past into a different future.
In an age of discontinuity we need Early Learning Systems that see the edge.
We need systems that compensate for our confirmation bias, using machine learning to reveal edges, visualise complexity, and entice us to look further than our filter bubbles. These are better machine generated reports. It is interactive, Early Learning Systems, that combine machine and human intelligence that allows us to see an edge that would otherwise remain unnoticed.
Addendum: Thanks to Per Espen Stoknes for his feedback on an early version of this text.